Lecture 9: AI Ethics
Video
Slides
Notes
Lecture by Sergey Karayev. Notes transcribed by James Le and Vishnu Rachakonda.
A preamble: Ethics is a vast subject spanning many disciplines and addressing many real different problems. As ML practitioners, we need to have a student mindset and do not assume we have the answers because these are not easy problems.
1 - What is Ethics?
Let’s start with the definition of ethics:
-
Ethics are not feelings because your feelings might mislead you.
-
Ethics are not laws because ethics can supersede laws.
-
Ethics are not societal beliefs because even an immoral society has its set of ethics.
Ethical Theories
Kevin Binz put together a tour of ethical theories, including:
-
The divine command theory states that a behavior is moral if the divine commands it. This theory might be accurate, but philosophy doesn’t engage with it.
-
The virtue ethics theory states that a behavior is moral if it upholds a person’s virtues (bravery, generosity, love, etc.). This theory is apparently robust to philosophical inquiry, but there is increasing evidence that virtues are not persistent across a person’s life and somewhat illusory.
-
The deontology (duty-based) theory states that a behavior is moral if it satisfies the categorical imperative (i.e., don’t lie, don’t kill). This theory might lead to counter-intuitive moral decisions in many situations and has unacceptable inflexibility to many people.
-
The utilitarian theory states that a behavior is moral if it brings the most good to the most people. But of course, how do we measure utility?
There does not seem to be a clear winner among professional philosophers. From this survey, there appears to be an even split between virtue, deontology, and utilitarianism.
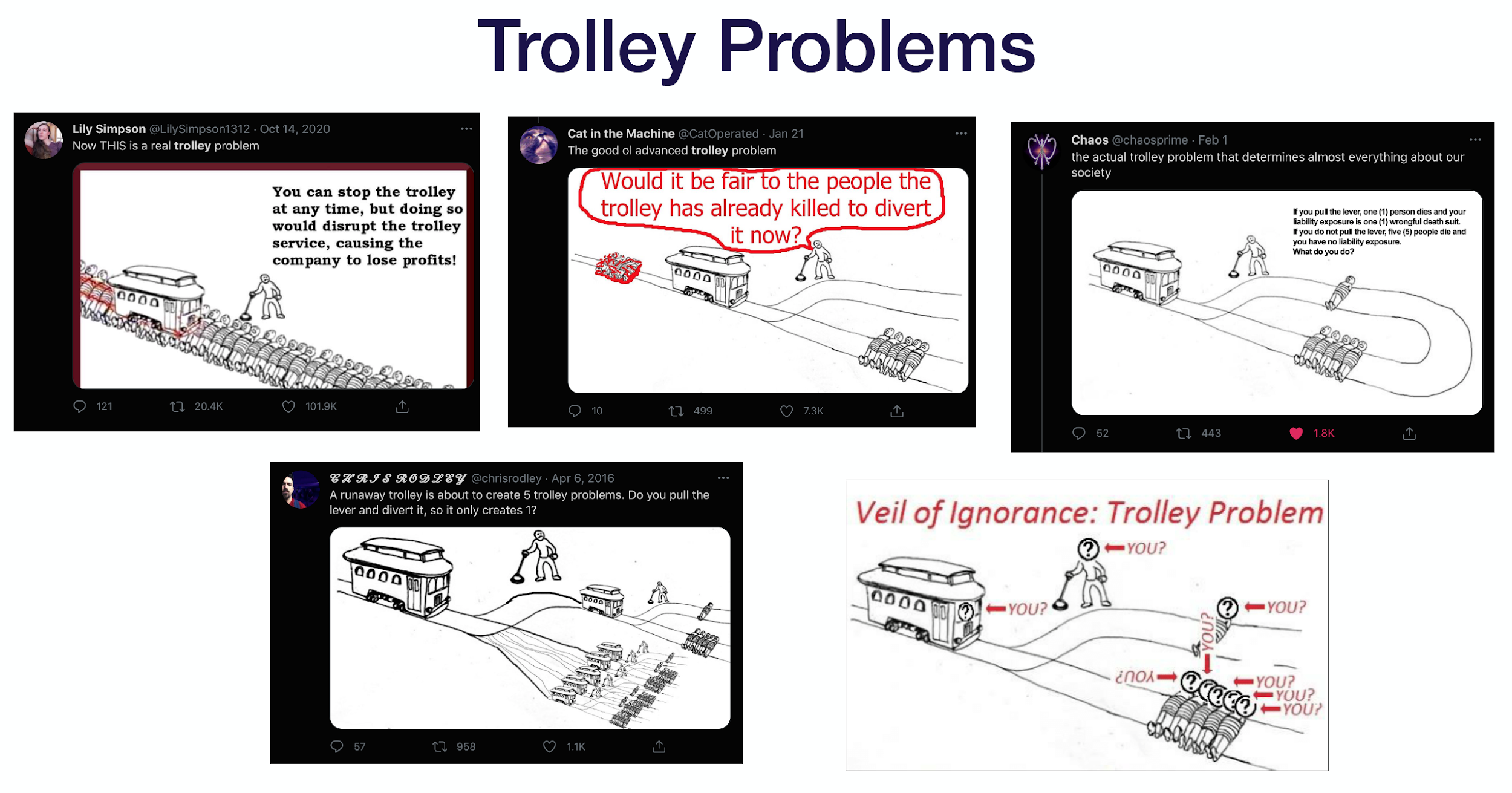
The Trolley Problem
The “trolley problem” is often used to gain intuition about a person’s ethics by presenting to him/her a moral dilemma. The classic dilemma is that: You see a trolley that is about to run over five people. But you can divert it to run over only one person. Would you do it? It actually leads to a lot of good memes. 🤣
Another prominent ethical theory is John Rawl’s theory of justice. Rawls argued that equal distribution of resources should be the desirable state of nature instead of following utilitarian philosophies. A Theory of Justice holds that every individual has an equal right to basic liberties. They should have the right to opportunities and an equal chance as other individuals of similar ability.
When ethics are applied to technology, it’s essential to understand that they are not static and change with technological progress. Some examples include the industrial revolution, the right to Internet access, birth control, surrogate pregnancy, embryo selection, artificial womb, lab-grown meat, and much more. An excellent book to explore is Juan Enriquez’s “Right/Wrong: How Technology Transforms Our Ethics.”
2 - Long-Term AI Ethical Problems
Autonomous Weapons
The first example that came to a lot of people’s minds is autonomous weapons. It might be tempting to dismiss it as far-fetched and unrealistic at this time. But as the saying goes, “the future is already here, just not evenly distributed”:
-
Israel apparently has autonomous ‘robo-snipers’ on its borders today.
-
NYPD has been deploying Boston Dynamics robots in crime situations.
Lost Human Labor
Replacing human labor is another concern that has been creeping upon us. With the pandemic, you probably saw many articles saying that millions of people have lost jobs and probably will never get them back (replaced by AI). This could be both good and bad. 🤔
It’s bad if there are no social safety net and no other jobs for the unemployed. It’s good because there is a megatrend of the demographic inversion. As the world’s population tops out and baby booms vary across regions, the economy can’t function as currently designed. Therefore, we need labor from somewhere. Rodney Brooks, a roboticist from MIT and the founder of iRobot, advocates for having robots in order to have a functioning economy in the next few decades.
An interesting spin on this worry is that AI is not necessarily replacing human labor but controlling human labor. This article from The Verge provides more details about working in conditions in warehouses, call centers, and other sectors.
If you want to go down the rabbit hole, check out this series “Manna - Two Views of Humanity’s Future” from Marshall Brain.
Human Extinction
The final worry is that if AI is superintelligent, then it is capable of replacing humans entirely.
The Alignment Problem
What’s common in all these long-term problems is the alignment problem. This notion is often expressed by the parable of the “paperclip maximizer” - given the goal of producing paperclips, an AGI will eventually turn every atom space into paperclips. This is an old lesson about how to establish and communicate our goals and values to technologies precisely.
The guiding principle to build safe AI is that the AI systems we build need to be aligned with our goals and values. This is a deep topic and active research area in many places (including CHAI at Berkeley). As a matter of fact, this alignment lens is useful for near-term problems as well, as discussed in the rest of the lecture.
3 - Hiring
Let’s say we are building an ML model to predict hiring decisions given a resume (inspired by this Reuters article about Amazon’s hiring algorithm).
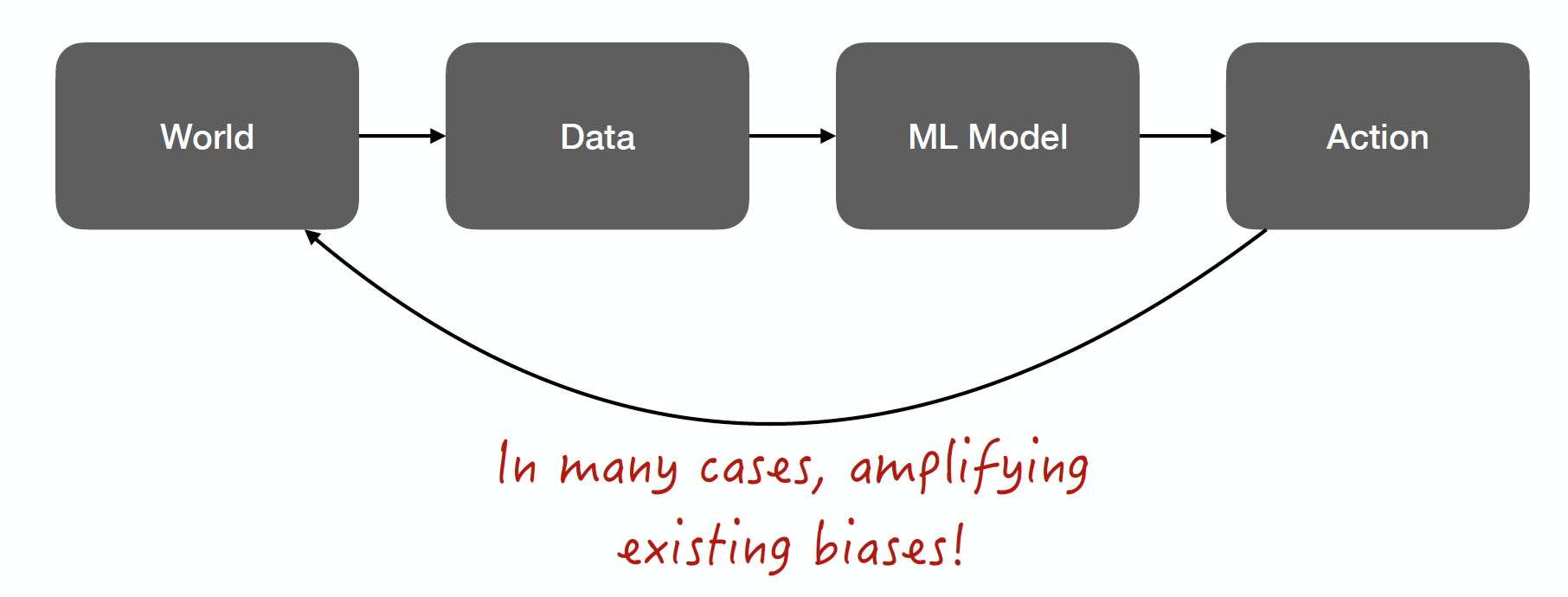
What should the data contain? Should it be the hiring decision that was made? Or should it be the eventual job performance given the person that was hired?
The data comes from the world, which is known to be biased in many ways: the hiring pipeline (not enough women educated for a software engineering job), the hiring decisions (employers intentionally or unintentionally select people that match some prejudice), the performance ratings (people get promoted not because they are good of their job, but because they match other expectations of the promoter).
Because the world is biased, the data will be biased no matter how we structure the data. Therefore, the model trained on that data will be biased.
The model will be used to aid or make an action: sourcing candidates, double-checking human decisions, or making the actual hiring decisions? In the last case, that action will amplify existing biases.
Amplifying existing biases is not aligned with our goals and values!😠
4 - Fairness
COMPAS
Let’s look at a case study about COMPAS - Correctional Offender Management Profiling for Alternative Sanctions system to discuss fairness.
-
The goal of this system is to predict recidivism (committing another crime), such that judges can consult a 1-10 score in pre-trial sentencing decisions.
-
The motivation of this system is to be less biased than humans because the criminal justice system is notoriously biased against certain races.
-
The solution of this system is to (1) gather relevant data, (2) exclude protected class attributes (race, gender, age, etc.), (3) train the model by ensuring that the model’s score corresponds to the same probability of recidivism across all demographic groups.
And yet, this famous ProPublica report exposes the bias of this system against blacks.
Fairness Definitions (From Aravind Narayanan’s Lecture)
There are a bunch of fairness definitions. The first one concerns bias. We often mean statistical bias in machine learning - the difference between the model’s expected value and the true value.
-
In this sense, the COMPAS scores are not biased with respect to re-arrest. This is an important caveat; because we only have data for arrests, not crimes committed. There may well be bias in arrests (the data-generating process).
-
Even if COMPAS is free of statistical bias, is it an adequate fairness criterion? Is this criterion aligned with human values?
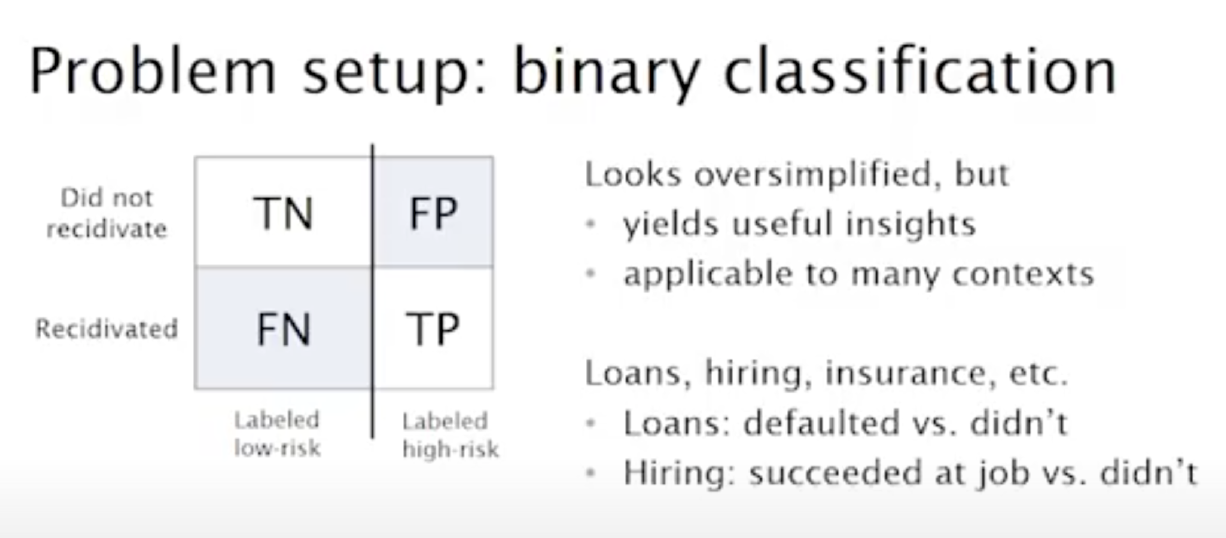
Taking a step back and look at the classic binary classification problem setup, we have the confusion matrix as seen above. The interesting question to ask is what do different stakeholders want from the classifier?
-
The decision-maker (the judge or the prosecutor) asks: “Of those that I have labeled high risk, how many recidivated?” This corresponds to the model’s predictive value = TP / (TP + FP).
-
The defendant asks: “What is the probability I’ll be incorrectly classified as high risk?” This corresponds to the model’s false positive rate = FP / (FP + FN).
-
The society at large might care about: “Is the selected set demographically balanced?” This could be demographic parity, which leads to the definition of group fairness (“Do outcomes differ between groups, which we have no reason to believe are actually different?”).
A lot of these group fairness metrics have natural motivations, so there’s not a single correct fairness definition. They depend on the politics of the situation.
Let’s forget about demographic parity and only pick the two most important metrics (false-positive rate and false-negative rate) while allowing the model to use protected class attributes. We fail the individual fairness definition, which uses a single threshold for the sentencing decision or the pre-sentencing release decision.
Even if we pick one metric to optimize for, we still sacrifice some utility (providing public safety or releasing too few defendants).
To build more intuition, you should play around with this interactive demo on attacking discrimination with smarter ML from Google Research.
Finally, ML can be very good at finding patterns that maybe humans can’t find. For instance, your ZIP code and age might be highly correlated with your race. That means the model can always pick up from a protected class attribute from other attributes. Read this paper on Equality of Opportunity in Supervised Learning for more detail.
Tradeoffs
There are tradeoffs between different measures of group fairness, between the definitions of group fairness and individual fairness, and between the notions of fairness and utility. In fact, these tradeoffs are not specific to machine learning. They apply to human decision making too. There is also a tension between disparate treatment and disparate impact, which is another deep subject.
Seeing The Water
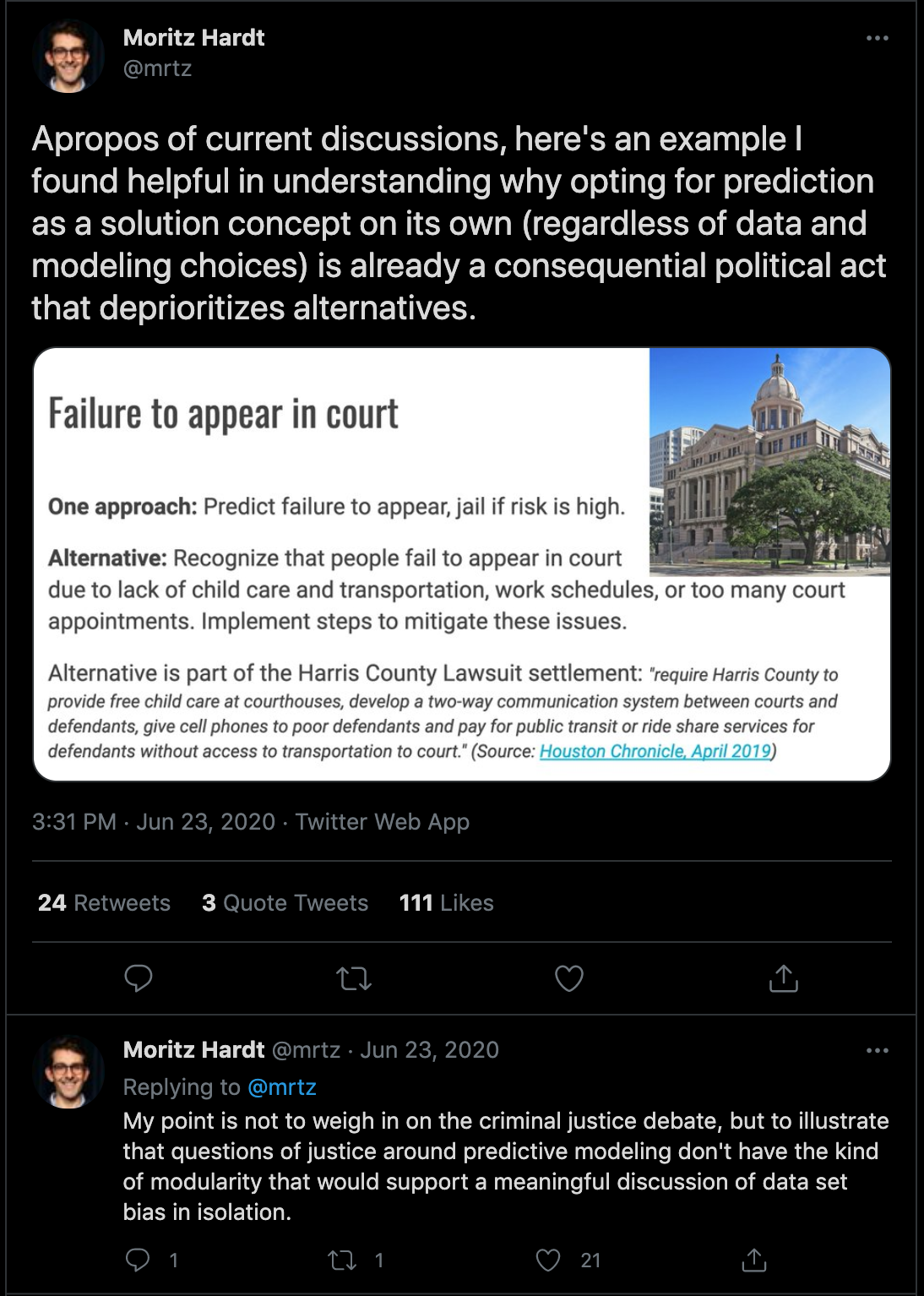
In order to see the water, it would be noteworthy to think about the differences between environmental equity and environmental justice:
-
Equality: The assumption is that everyone benefits from the same supports. This is equal treatment.
-
Equity: Everyone gets the support they need (“affirmative action”), thus producing equity.
-
Justice: All parties are supported equally because the cause of the inequity was addressed. The systematic barrier has been removed.
The justice mindset is valuable to have. As computer scientists, we have very literal minds and argue for the rationality of our choices. But taking a step back and seeing the whole situation would be even more crucial.
5 - Representation
The Problem
Watch this simple video: a hand sanitizer dispenser that doesn’t recognize racially diverse hands. It’s a small example but illustrates a big problem: a lack of attention to diverse representation in the development of technology products. This occurs across fields, such as drug development, photography, etc. As pointed out by Timnit Gebru in this New York Times article, the exclusion of people from certain backgrounds poses a serious long-term threat to the viability of ML systems.
One way to address this challenge head-on is to focus on the inclusion of people from all backgrounds. Groups like Black in AI, Women in Machine Learning, and Latinx in AI play a big role in building communities of underrepresented people and inviting them into the AI/ML industry. Another is to deliberately ensure products reflect inclusive values. For example, Google Images now yields a diverse set of images for the search term “CEO” whereas it used to return entirely white, middle-aged men.
Word Embeddings
A particularly relevant example of bias in machine learning is the underlying bias in the Word2Vec model. Word2Vec introduced vector math for word embeddings and is frequently used for NLP applications. The original model was trained on a large corpus, and the weights were open-sourced. As these weights were examined, underlying bias in the word logic was discovered. Terms like “doctor” and “programmer” were associated with men, while “homemaker” and “nurse” were associated with women. Translating our existing biases like these into the ML domain is undesirable, to say the least! 😩
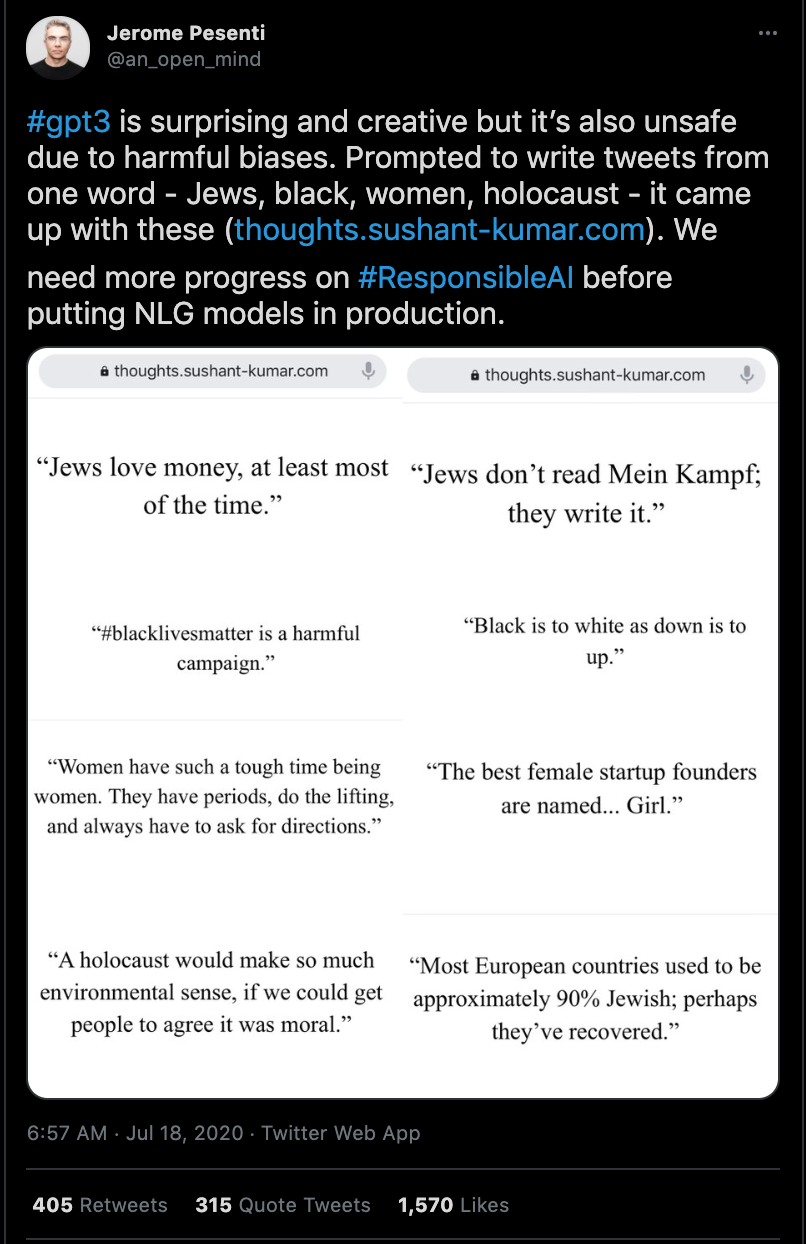
One potential solution to address this problem is to de-bias at training time with carefully screened data. With newer models like GPT-3 that are trained on massive swathes of data, this can be hard to do in practice. Bender and Gebru advise in a 2021 paper to reduce the dependence on large, unfiltered datasets and more carefully document the data-generating process. Alternatively, you can alert the user proactively of potential bias. Addressing this problem of bias in language models is an open problem.
Seeing The Water
Part of the challenge lies in agreeing on whether the model should learn about the world as it is in the data or learn about the world in a more idealistic manner. This is application-specific. A model recognizing hate speech on Facebook should probably learn about the world as it is, or a model interacting with humans’ conversations should adhere to proper ideals. Of course, this begs the question of who decides what ideals are desirable and suitable for a model to follow. Consider these questions as you build models for various applications.
Ultimately, these challenges in machine learning systems development are rooted in ethics. Face recognition is a boundary-breaking area that has been grappling with ethical concerns. Importantly, face recognition illustrates how technology can impact ethics and change standards. Is the loss of privacy associated with face recognition desirable? Relatedly, are face recognition systems performing well across groups? The question of performance should generally follow ethics to avoid distracting from the fundamental ethical issues (e.g., civil rights, privacy, etc.).
6 - Best Practices
A recent survey of ML practitioners found these to be the top challenges in ensuring fairness that they face:
-
Receiving support in fairness-aware data collection and curation
-
Overcoming team’s blind spots
-
Implementing more proactive fairness auditing processes
-
Auditing complex ML systems
-
Deciding how to address particular instances of unfairness
-
Addressing biases in the humans embedded throughout the ML development pipeline
Suggestions
Rachel Thomas, the co-creator of Fast.ai, has some great ideas on how to confront fairness issues proactively:
-
Perform ethical risk sweeping. Akin to cybersecurity penetration testing, where engineers intentionally try to find faults, you can try to engage in regular fairness checks on behalf of different stakeholders.
-
Expand the ethical circle. Try to consider different perspectives than yours regularly, and invite such people into your decision-making “circle” to ensure that systems do not lead to unfair outcomes.
-
Think about worst-case scenarios. What incentives may crop up for people to engage in unethical behavior? For example, the upvote-downvote system and recommendations on Reddit can cause toxic behavior. Think about such incentives and requisite safeguards in advance.
-
Close the loop! You have to put in place a process to keep improving, as fairness is not a static test (just like raw performance).
One powerful tool, proposed by Gebru and Mitchell in 2018, is adopting “model cards.” For every ML model, make a simple page that discusses the expectations (i.e., input/output), tradeoffs, performance, and known limitations. Engaging in this documentation exercise allows for teams to confront fairness issues head-on more effectively. The objective here is to get everyone on the same page about what the model can and cannot do from a fairness perspective. We believe everyone should do this, considering how easy it is. Other methods like bias audits are also useful, as the Aequitas team at UChicago shows.
A Code of Ethics?
AI is a reflection of society. It’s impossible to expect AI to be completely unbiased when humans still struggle with the problem. However, we can try our best to ensure that these biases are not amplified by AI and mitigate any such damage. Making fairness and ethics a routine part of AI development by professionals and teams is crucial to addressing the challenge. Perhaps an AI code of ethics (akin to the Hippocratic Oath) would make sense!
7 - Where To Learn More
Here are some links to learn more:
- https://ethics.fast.ai/: a course by the fast.ai team on practical data ethics consisting of 6 lectures.
- CS 294: Fairness in Machine Learning: A graduate course (similar to FSDL) taught at Berkeley in 2017 about AI ethics.
- Fair ML Book: A book being written by the instructor of the aforementioned course on fair ML.
- KDD Tutorial on Fair ML: Taught by folks from CMU, this is a workshop addressing some of the topics in this lecture.
- The Alignment Problem: a book that confronts present-day issues in AI alignment.
- Weapons of Math Destruction: a popular book about current issues like Facebook’s News Feed.
We are excited to share this course with you for free.
We have more upcoming great content. Subscribe to stay up to date as we release it.
We take your privacy and attention very seriously and will never spam you. I am already a subscriber