Cloud GPUs
Discussion of this page on Hacker News, May 21, 2023.
Training and running neural networks often requires hardware acceleration, and the most popular hardware accelerator is the venerable graphics processing unit, or GPU.
We have assembled cloud GPU vendor pricing all into tables, sortable and filterable to your liking!
We have split the vendor offerings into two classes:
- GPU Cloud Servers, which are long-running (but possibly pre-emptible) machines, and
- Severless GPUs, which are machines that scale-to-zero in the absence of traffic (like an AWS Lambda or Google Cloud Function)
We welcome your help in adding more cloud GPU providers and keeping the pricing info current.
Please file an issue or make a pull request to this repo, editing this file to update the text on this page or one of the CSV files to update the data: cloud-gpus.csv for servers and serverless-gpus.csv for serverless options.
GPU Cloud Server Comparison
Notes
The table below does not include all possible configurations for all providers, as providers differ in their configuration strategy.
- Most providers, including AWS, Azure, and Lambda, provide instances with pre-set configurations.
- On GCP, any suitable machine can be connected to a configuration of GPUs.
- On other providers, like Oblivus Cloud, Cudo Compute, and RunPod, users have precise control over the resources they request. Note that RunPod's Community Cloud, Oblivus, and Cudo are all "open clouds", meaning compute is provided by third parties.
- For providers without pre-set instance configurations, we have selected configurations that are roughly equivalent to AWS's options. Generally, these configurations are good for workloads that require heavy inter-GPU communication.
- Where possible, regions were set to be the west or central parts of the United States. GPU availability depends on the region.
- Raw data can be found in a csv on GitHub.
- Costs can be substantially reduced via preemption recovery and failover across clouds. If you don't want to roll your own, consider a tool like SkyPilot. See discussion of their launch on Hacker News, December 13, 2022.
Serverless GPUs
Notes
We use the classic definition of "serverless", courtesy of the original AWS announcement on serverless computing: no server management, flexible scaling, high availability, and no idle capacity. We only include services that fit this criterion in our options below.
Furthermore, we only include services that provide serverless GPUs, which can be used to run custom workloads, not just inference in particular models as a service.
- Direct price comparisons are trickier for serverless offerings: cold boot time and autoscaling logic can substantially impact cost-of-traffic.
- Some of the providers allow configuration of CPU and RAM resources. We have selected reasonable defaults, generally comparable to the fixed offerings of other providers.
- You can find pricing pages for the providers here: Banana, Baseten, Beam, Covalent, Modal, OVHcloud, Replicate, RunPod, Thunder Compute
- Serverless GPUs are a newer technology, so the details change quickly and you can expect bugs/growing pains. Stay frosty!
- Raw data can be found in a csv on GitHub.
How do I choose a GPU?
This page is intended to track and make explorable the current state of pricing and hardware for cloud GPUs.
If you want advice on which machines and cards are best for your use case, we recommend Tim Dettmer's blog post on GPUs for deep learning.
The whole post is a tutorial and FAQ on GPUS for DNNs, but if you just want the resulting heuristics for decision-making, see the "GPU Recommendations" section, which is the source of the chart below.
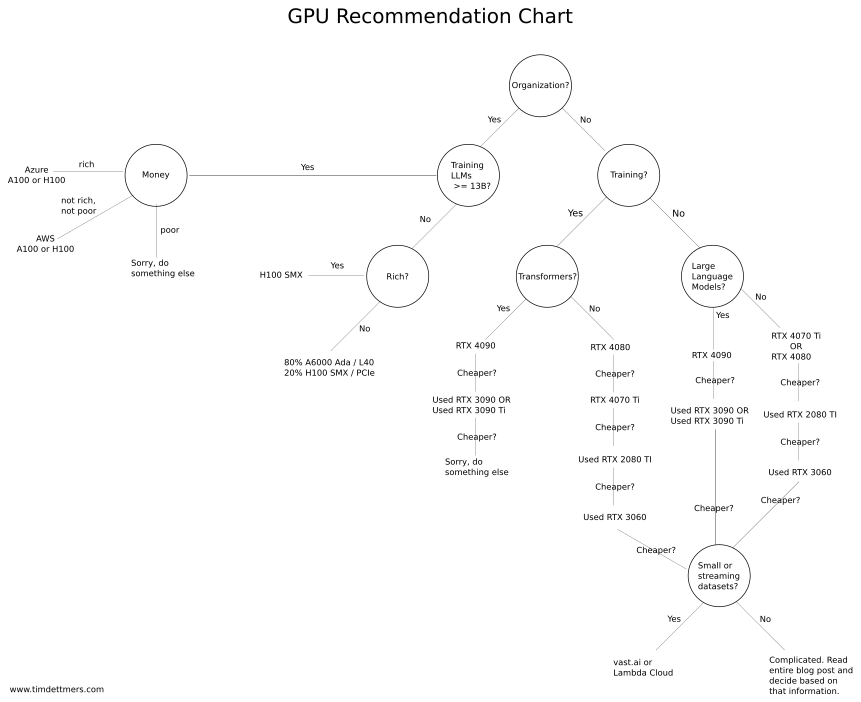
Flowchart for quickly selecting an appropriate GPU for your needs, by Tim Dettmers
GPU Raw Performance Numbers and Datasheets
Below are the raw TFLOPs of the different GPUs available from cloud providers.
| Model | Arch | FP32 | Mixed-precision | FP16 | Source |
|---|---|---|---|---|---|
| H100 | Hopper | 51 | 756 | 1513 | Datasheet |
| A100 | Ampere | 19.5 | 156 | 312 | Datasheet |
| A10G | Ampere | 35 | 35 | 70 | Datasheet |
| A6000 | Ampere | 38 | ? | ? | Datasheet |
| V100 | Volta | 14 | 112 | 28 | Datasheet |
| T4 | Turing | 8.1 | 65 | ? | Datasheet |
| P4 | Pascal | 5.5 | N/A | N/A | Datasheet |
| P100 | Pascal | 9.3 | N/A | 18.7 | Datasheet |
| K80 | Kepler | 8.73 | N/A | N/A | Datasheet |
| A40 | Ampere | 37 | 150 | 150 | Datasheet |
GPU Performance Benchmarks
Below are some basic benchmarks for GPUs on common deep learning tasks.

Benchmark of different GPUs on a single ImageNet epoch, by AIME
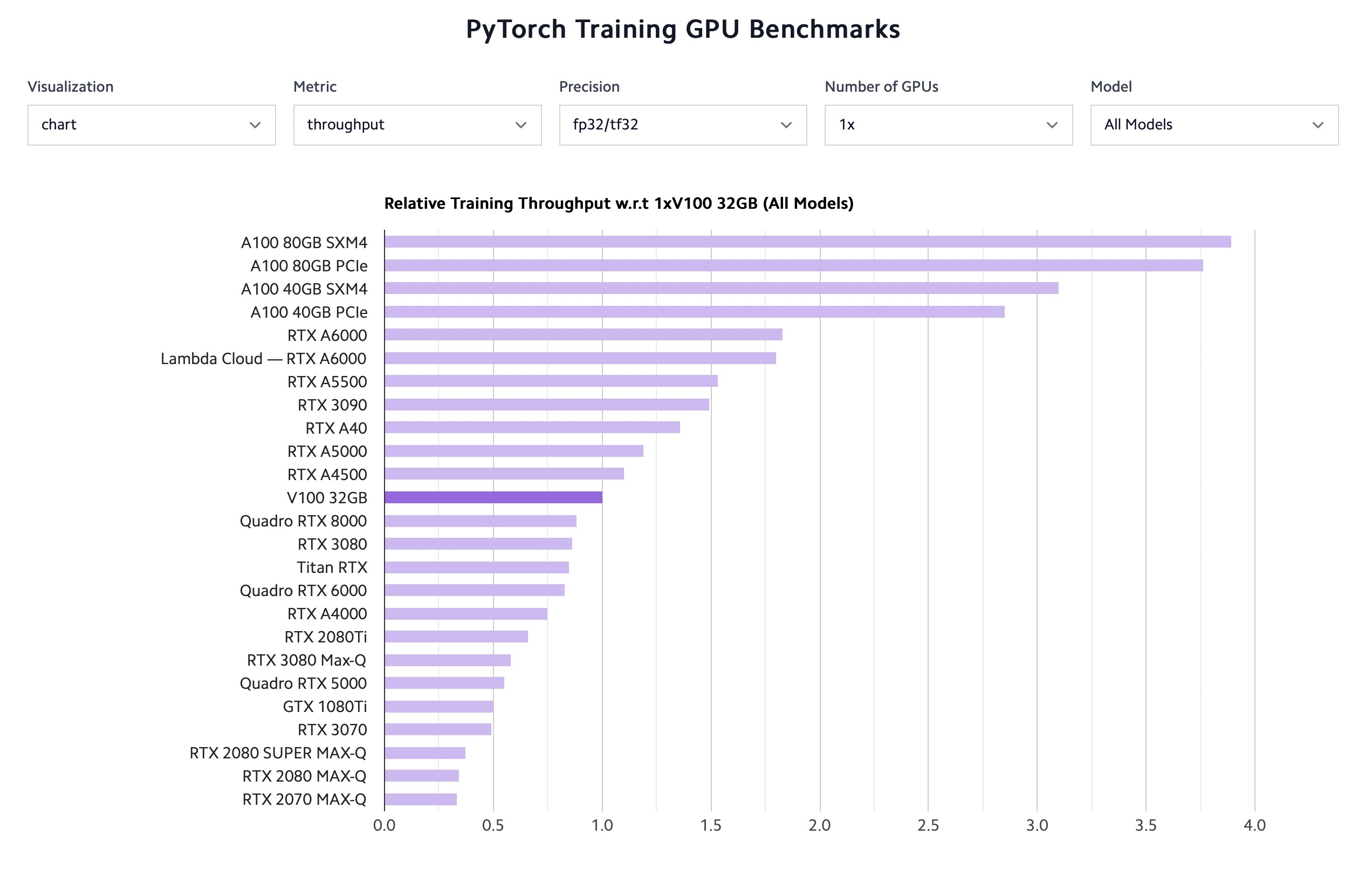
Benchmark of different GPUs on a mix of tasks, by Lambda Labs
We are excited to share this course with you for free.
We have more upcoming great content. Subscribe to stay up to date as we release it.
We take your privacy and attention very seriously and will never spam you. I am already a subscriber