Lecture 8: Data Management
Video
Slides
Notes
Lecture by Sergey Karayev. Notes transcribed by James Le and Vishnu Rachakonda.
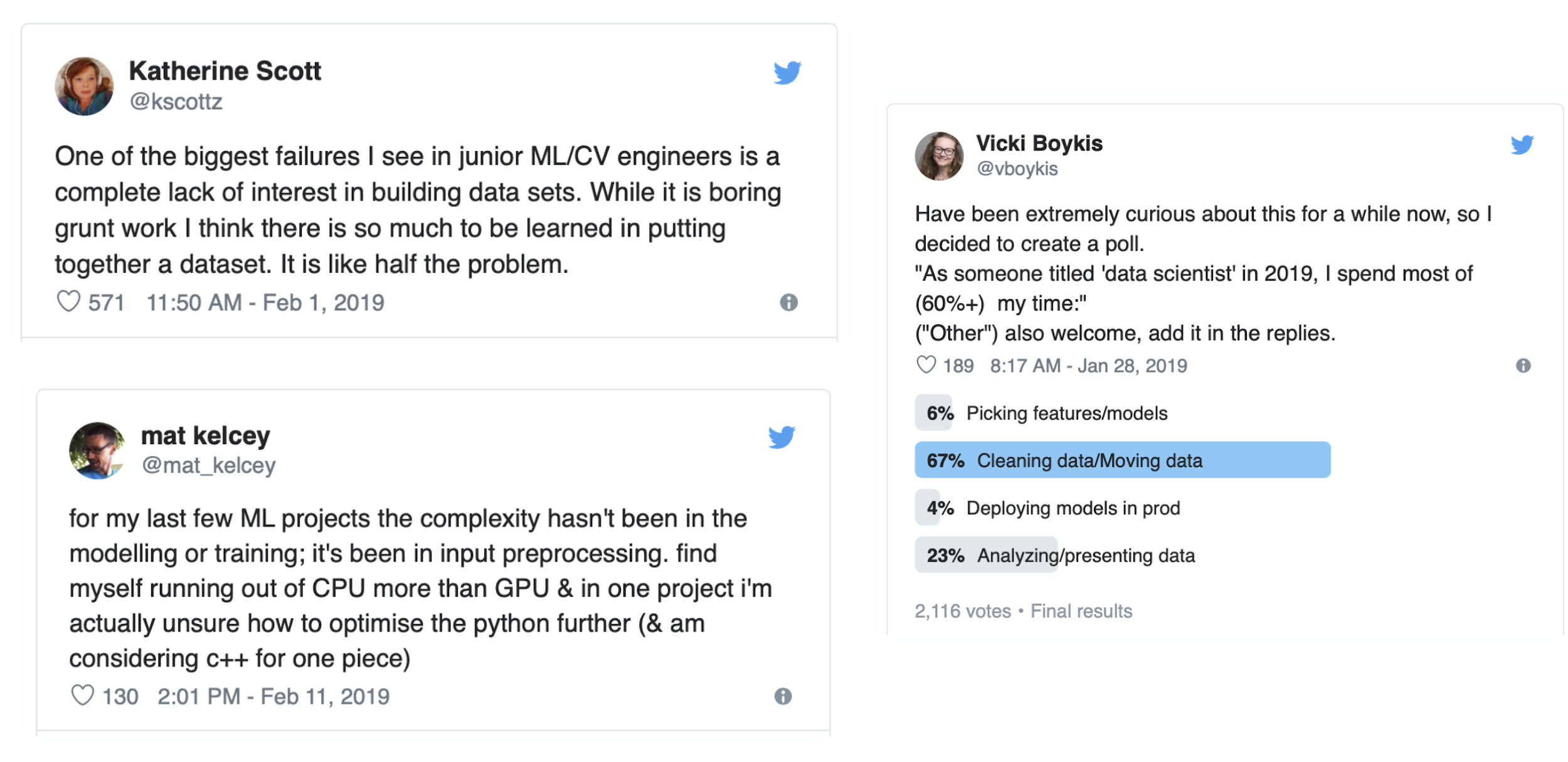
One of the best data science articles written in 2019 is “Data science is different now” by Vicki Boykis. Part of the article is a collection of tweets from other data science and machine learning practitioners.
1 - Data Management Overview
When we think about what data management for deep learning entails, there might be many different data sources: images on S3, text files on a file system, logs spread across different machines, and maybe even records in a database. At some point, you need to get all of that data over to a local filesystem next to GPUs. The way you will get data over to that trainable format is different for every project and every company. For instance:
-
Maybe you train your images on ImageNet, and all the images are just S3 URLs. Then, all you have to do is download them over to the local filesystem.
-
Maybe you have a bunch of text files that you crawled yourself somewhere. You want to use Spark to process them on a cluster and Pandas data frame to analyze/select subsets that will be used in the local filesystem.
-
Maybe you collect logs and records from your database into a data lake/warehouse (like Snowflake). Then, you process that output and convert them into a trainable format.
There are countless possibilities that we are not going to cover completely in this lecture, but here are the key points to remember:
-
Let the data flow through you: You should spend 10x as much time as you want to on exploring the dataset.
-
Data is the best way to improve your overall ML project performance: Instead of trying new architectures or kicking off the hyper-parameter search, adding more data and augmenting the existing dataset will often be the best bang to your buck.
-
Keep It Simple Stupid: We will discuss complex pipelines and new terms, but it’s important to not over-complicate things and make data management a rocket science.
2 - Data Sources
So, where do the training data come from? Most deep learning applications require lots of labeled data (with exceptions in applications of reinforcement learning, GANs, and GPT-3). There are publicly available datasets that can serve as a starting point, but there is no competitive advantage of using them. In fact, most companies usually spend a lot of money and time labeling their own data.
Data Flywheel
Data flywheel is an exciting concept: if you can get your models in front of the users, you can build your products in a mechanism that your users contribute good data back to you and improve the model predictions. This can enable rapid improvement after you get that v1 model out into the real world.
Semi-Supervised Learning
Semi-supervised learning is a relatively recent learning technique where the training data is autonomously (or automatically) labeled. It is still supervised learning, but the datasets do not need to be manually labeled by a human; but they can be labeled by finding and exploiting the relations (or correlations) between different input signals (that is, input coming from different sensor modalities).
A natural advantage and consequence of semi-supervised learning are that this technique can be performed in an online fashion (given that data can be gathered and labeled without human intervention) more easily (with respect to, e.g., supervised learning), where models can be updated or trained entirely from scratch. Therefore, semi-supervised learning should also be well suited for changing environments, changing data, and, in general, changing requirements.
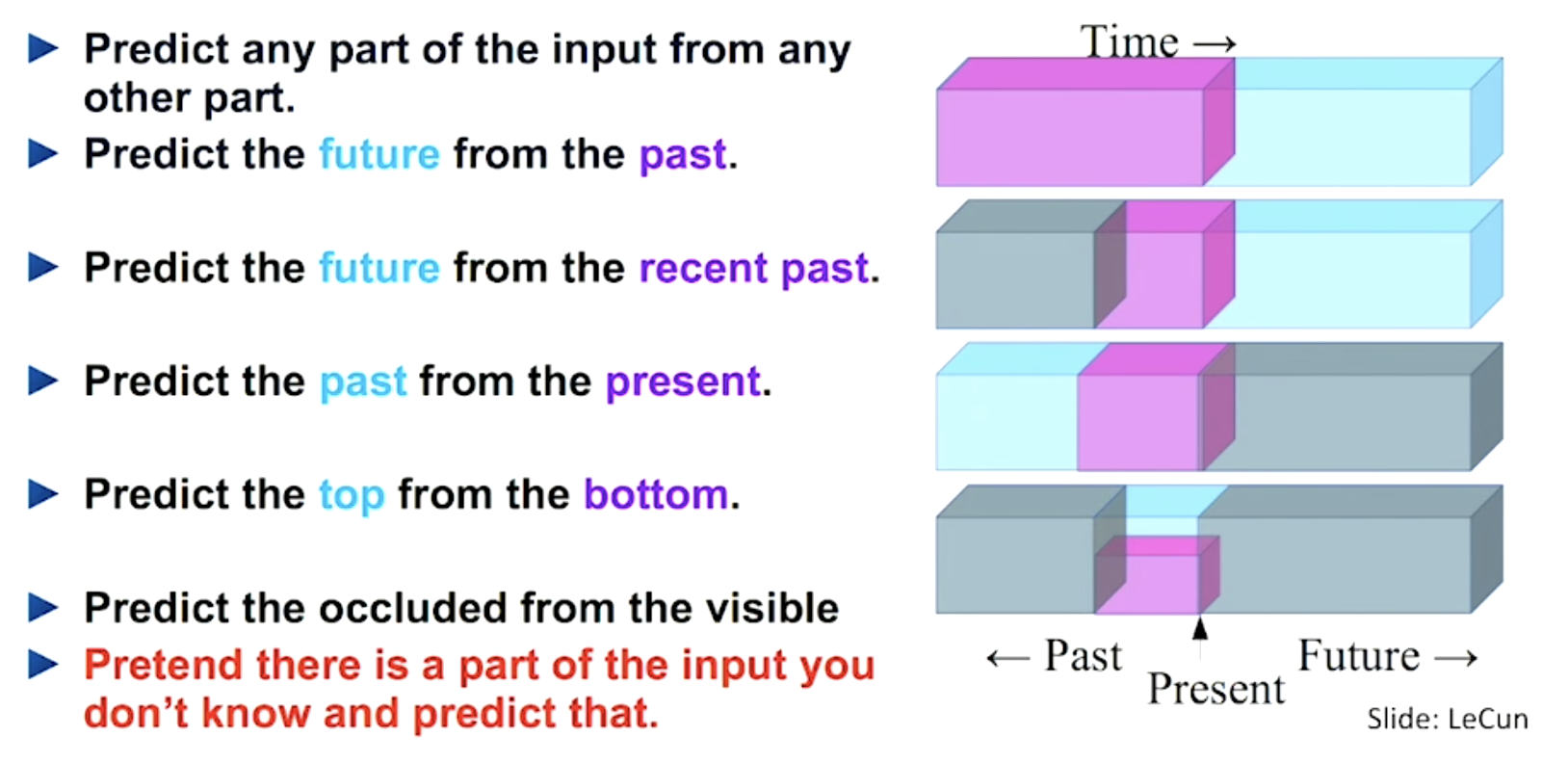
For a text example, you can predict the future words from the past words, predict the beginning of a sentence from the end of a sentence, or predict the middle word of a sentence from the words surrounding it. You can even examine whether two sentences occur in the same paragraph in the same corpus of your training data. These are different ways to formulate the problem, where you don’t need to label anything and simply use the data to supervise itself.
This technique also applies to vision. Facebook AI recently released a model called SEER trained on 1 billion random images from the Internet. Yet, SEER achieved state-of-the-art accuracy on the ImageNet top-1 prediction task.
If you’re interested in learning more about semi-supervised learning, check out:
-
Lilian Weng's "Self-Supervised Learning" post
-
Facebook AI’s “Self-Supervised Learning: The Dark Matter Of Intelligence” post
-
Facebook AI’s VISSL library for the SEER algorithm
Data Augmentation
Recent advances in deep learning models have been largely attributed to the quantity and diversity of data gathered in recent years. Data augmentation is a strategy that enables practitioners to significantly increase the diversity of data available for training models without actually collecting new data. Data augmentation techniques such as cropping, padding, and horizontal flipping are commonly used to train large neural networks. In fact, they are mostly required for training computer vision models. Both Keras and fast.ai provide functions that do this.

Data augmentation also applies to other types of data.
-
For tabular data, you can delete some cells to simulate missing data.
-
For text, there are no well-established techniques, but you can replace words with synonyms and change the order of things.
-
For speech and video, you can change speed, insert a pause, mix different sequences, and more.
If you’re interested in learning more about data augmentation, check out:
-
Berkeley AI’s “1000x Faster Data Augmentation” post
-
Edward Ma’s “nlpaug” repository
Synthetic Data
Related to the concept of data augmentation is synthetic data, an underrated idea that is almost always worth starting with. Synthetic data is data that’s generated programmatically. For example, photorealistic images of objects in arbitrary scenes can be rendered using video game engines or audio generated by a speech synthesis model from the known text. It’s not unlike traditional data augmentation, where crops, flips, rotations, and distortions are used to increase the variety of data that models have to learn from. Synthetically generated data takes those same concepts even further.
Most of today’s synthetic data is visual. Tools and techniques developed to create photorealistic graphics in movies and computer games are repurposed to create the training data needed for machine learning. Not only can these rendering engines produce arbitrary numbers of images, but they can also produce annotations too. Bounding boxes, segmentation masks, depth maps, and any other metadata is output right alongside pictures, making it simple to build pipelines that produce their own data.
Because samples are generated programmatically along with annotations, synthetic datasets are far cheaper to produce than traditional ones. That means we can create more data and iterate more often to produce better results. Need to add another class to your model? No problem. Need to add another key point to the annotation? Done. This is especially useful for applications in driving and robotics.

If you’re interested in learning more about synthetic data, check out:
-
Dropbox’s “Creating A Modern OCR Pipeline Using Computer Vision and Deep Learning” post
-
Andrew Moffat’s “metabrite-receipt-tests” repository
-
Microsoft’s AirSim simulator
-
OpenAI’s “Ingredients For Robotics Research” post
3 - Data Storage
Data storage requirements for AI vary widely according to the application and the source material. Datasets in intelligence, defense, medical, science, and geology frequently combine petabyte-scale storage volumes with individual file sizes in the gigabyte range. By contrast, data used in areas such as supply chain analytics and fraud detection are much smaller.
There are four building blocks in a data storage system:
-
The filesystem
-
The object storage
-
The database
-
The data lake or data warehouse
Filesystem
The filesystem is the foundational layer of storage.
-
Its fundamental unit is a “file” — which can be text or binary, is not versioned, and is easily overwritten.
-
A file system can be as simple as a locally mounted disk containing all the files you need.
-
More advanced options include networked filesystems (NFS), which are accessible over the network by multiple machines, and distributed file systems (HDFS) which are stored and accessed over multiple machines.
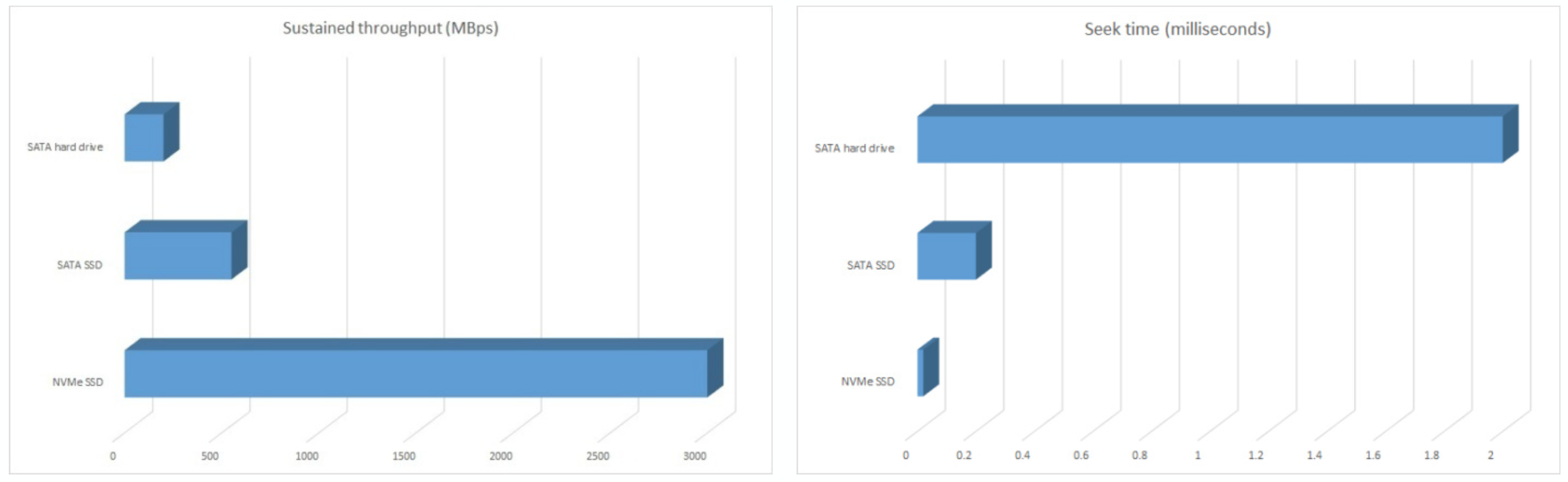
The plots above display hard-drive speeds for SATA hard drive, SATA SSD, and NVMe SSD.
-
The left plot shows the sustained throughput in MBps (how much information to copy a file): The latest iteration of hard drive technology (NVMe) is 6-10x more powerful than older iterations.
-
The right plot shows the seek time in milliseconds (how long it takes to go to a file on disk): The NVMe is 25-30x faster than the old-school ones.
What format should we store data in?
-
For binary data (images, audios, videos), just files are enough. In Tensorflow, you have the TFRecord format to batch binary files, which does not seem to be necessary with the NVMe hard drives.
-
For large tabular and text data, you have two choices:
-
HDF5 is powerful but bloated and declining.
-
Parquet is widespread and recommended.
-
Feather is an up-and-coming open-source option powered by Apache Arrow.
-
-
Both Tensorflow and PyTorch provide their native dataset class interfaces (tf.data and PyTorch DataLoader).
Object Storage
Object storage is an API over the filesystem that allows users to use a command on files (GET, PUT, DELETE) to a service without worrying where they are actually stored.
-
Its fundamental unit is an “object,” which is usually binary (images, sound files…).
-
Object storage can be built with data versioning and data redundancy into the API.
-
It is not as fast as local files but fast enough within the cloud.
Database
A database is a persistent, fast, scalable storage and retrieval of structured data.
-
Its fundamental unit is a “row” (unique IDs, references to other rows, values in columns).
-
Databases are also known for online transaction processing (OLTP). The mental model here is that everything is actually in memory, but the software ensures that everything is logged to disk and never lost.
-
Databases are not built for binary data, so you must store the references (i.e., S3 URLs) instead.
Here are our recommendations:
-
PostgreSQL is the right choice most of the time, thanks to the support of unstructured JSON.
-
SQLite is perfectly good for small projects.
-
“NoSQL” was a big craze in the 2010s (like MongoDB). However, they are not as fast as the relational database and also have consistency issues frequently.
-
Redis is handy when you need a simple key-value store.
Data Warehouse
A data warehouse is a structured aggregation of data for analysis, known as online analytical processing (OLAP).
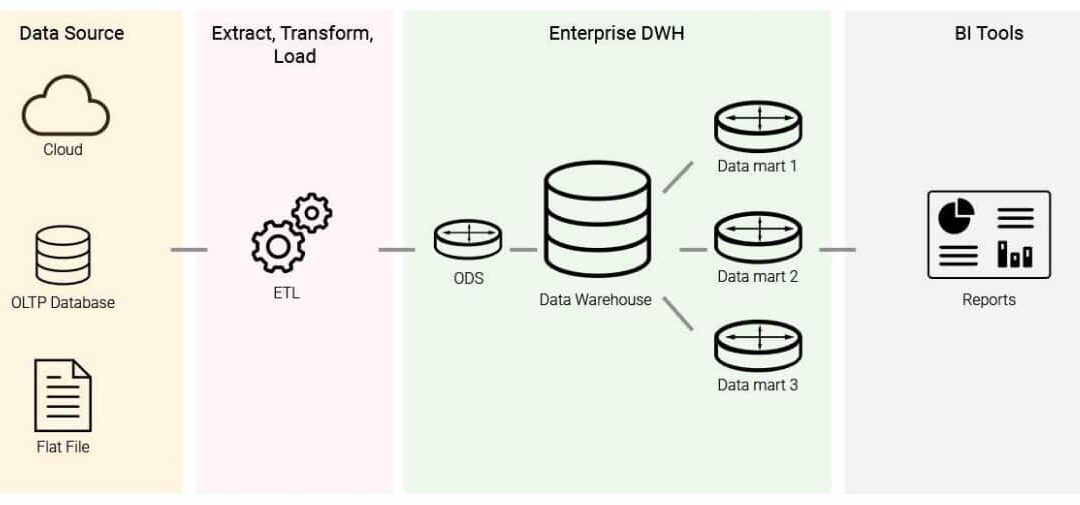
Another acronym that you might have heard of is ETL (Extract, Transform, Load). The idea here is to extract data from data sources, transform the data into a common schema, and load the schema into the data warehouse. You can load the subset from the warehouse that you need and generate reports or run analytical queries. Well-known enterprise options in the market are Google BigQuery, Amazon Redshift, and Snowflake.
SQL and DataFrames
Most data solutions use SQL as the interface to the data, except for some (like Databricks) that use DataFrames. SQL is the standard interface for structured data. But in the Python ecosystem, Pandas is the main DataFrame. Our advice is to become fluent in both.
Data Lake
A data lake is the unstructured aggregation of data from multiple sources (databases, logs, expensive data transformations). It operates under the concept of ELT (Extract, Load, Transform) by dumping everything in the lake and transforming the data for specific needs later.
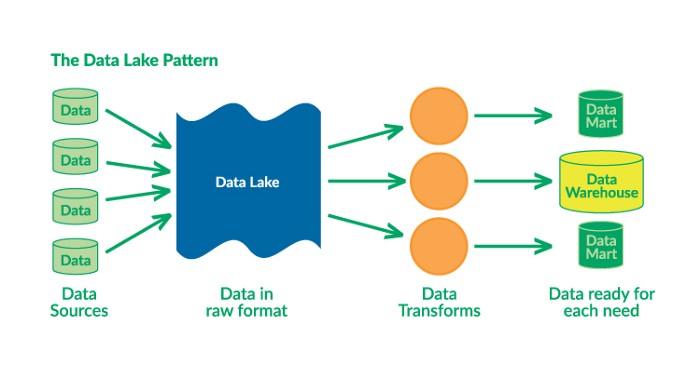
Data “Lakehouse”
The current trend in the field is to combine data warehouses and data lakes in the same suite. The Databricks Lakehouse Platform is both a warehouse and a lake, operated as an open-source project called Delta Lake. You can store both structured and unstructured data in the platform and use them for analytics workloads and machine learning engines.
What Goes Where?
-
Binary data (images, sound files, compressed texts) are stored as objects.
-
Metadata (labels, user activity) is stored in a database.
-
If we need features that are not obtainable from the database (logs), we would want to set up a data lake and a process to aggregate the data required.
-
At training time, we need to copy the necessary data to the filesystem on a fast drive.
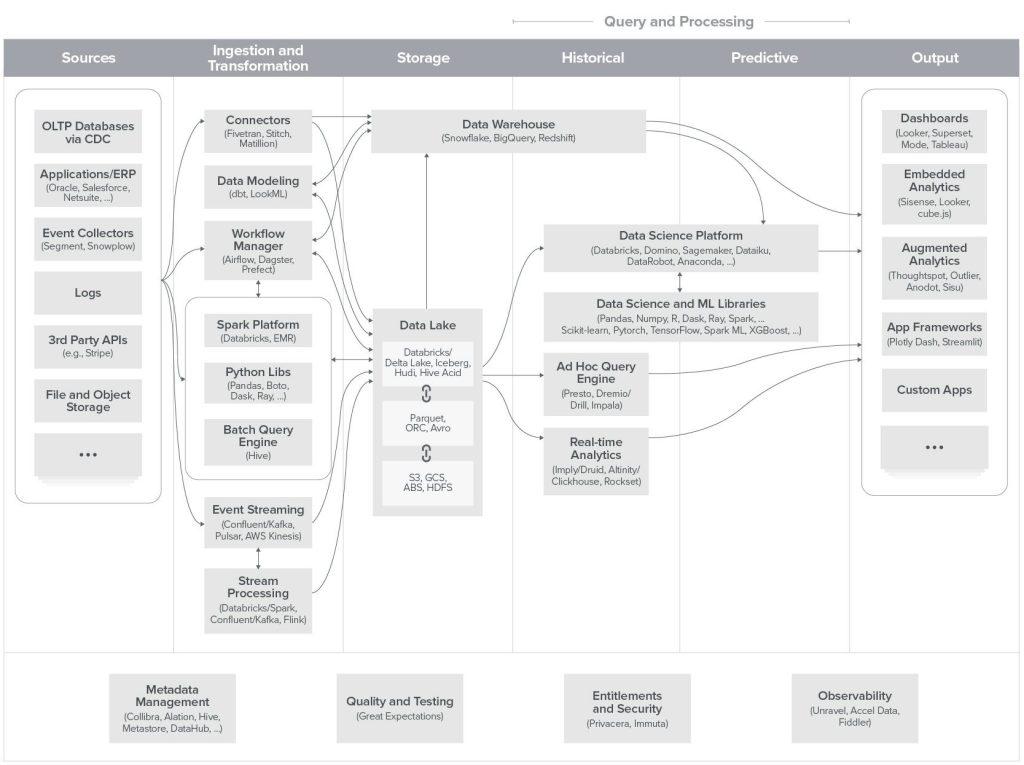
A lot is going on within the data management tooling and infrastructure. We recommend looking at a16z’s “Emerging Architectures For Modern Data Infrastructure” article to get a broad look into this ecosystem.
A highly recommended resource is Martin Kleppmann’s book “Designing Data-Intensive Applications,” which provides excellent coverage of tools and approaches to build reliable, scalable, and maintainable data storage systems.
4 - Data Processing
Data Dependencies
Let’s look at a motivational example of training a photo popularity predictor every night. For each photo, the training data must include these components:
-
Metadata (such as posting time, title, location) that is in the database.
-
Some features of the user (such as how many times they logged in today) that need to be computed from logs.
-
Outputs of photo classifiers (such as content, style) that can be obtained after running the classifiers.
The idea is that we have different sources of data, and they have different dependencies. The big hurdle here is that some tasks can’t be started until other tasks are finished. Finishing a task should “kick-off” its dependencies.
The simplest thing we can do is a “Makefile” to specify what action(s) depend on. But here are some limitations to this approach:
-
What if re-computation needs to depend on content, not on a date?
-
What if the dependencies are not files but disparate programs and databases?
-
What if the work needs to be spread over multiple machines?
-
What if many dependency graphs are executing all at once, with shared dependencies?
MapReduce

The old-school big data solutions to this are Hadoop and Apache Spark. These are MapReduce implementations, where you launch different tasks that each take a bit of the data (Map) and reduce their outputs into a single output (Reduce). Both Hadoop and Spark can run data processing operations and simple ML models on commodity hardware, with tricks to speed things up.
In the modern environment, you can’t run an ML model (in PyTorch or TensorFlow) as part of running a Spark job (unless that model itself is programmed in Spark). That’s when you need a workflow management system like Apache Airflow.
DAG
In Airflow, a workflow is defined as a collection of tasks with directional dependencies, basically a directed acyclic graph (DAG). Each node in the graph is a task, and the edges define dependencies among the tasks. Tasks belong to two categories: (1) operators that execute some operation and (2) sensors that check for the state of a process or a data structure.
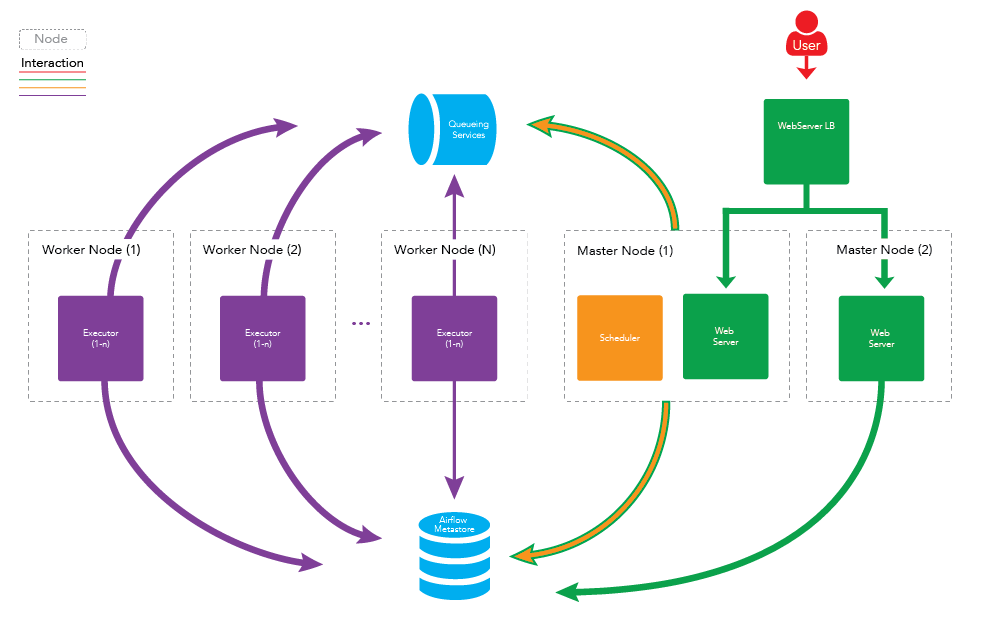
The main components of Airflow include: (1) a metadata database that stores the state of tasks and workflows, (2) a scheduler that uses the DAGs definitions together with the state of tasks in the metadata database to decide what needs to be executed, and (3) an executor that determines which worker will execute each task.
Besides Airflow, here are other notable solutions:
-
Apache Beam: The TensorFlow team uses Apache Beam to generate big datasets and run those processing steps on Google Cloud Dataflow (a cloud orchestrator).
-
Prefect: A similar idea to Airflow, Prefect is a Python framework that makes it easy to combine tasks into workflows, then deploy, schedule, and monitor their execution through the Prefect UI or API.
-
dbt: dbt provides this data processing ability in SQL (called “analytics engineering.”)
-
Dagster: Dagster is another data orchestrator for ML, analytics, and ETL. You can test locally and run anywhere with a unified view of data pipelines and assets.
5 - Feature Store
Feature stores were first popularized by the ML team at Uber as part of their Michelangelo platform. Traditionally, ML systems are divided into two portions, offline processing and online processing.
-
For the initial work of modeling, data that is generally static, perhaps stored in a data lake. Using some preprocessing methods (usually in SQL or Spark), data, which could be logfiles, requests, etc., are converted into features used to develop and train the model. The end result of this process is a model trained on a static sample of the data. This is an offline process.
-
In contrast, the process of performing inference (e.g., Uber’s need to return ride prices in real-time) often works with real-time data in an online process fashion. From a technology standpoint, whereas the offline use case might involve a data lake and Spark/SQL, the online processing use case involves technologies like Kafka and Cassandra that support speedier processing of creating or accessing the features required to perform inference.
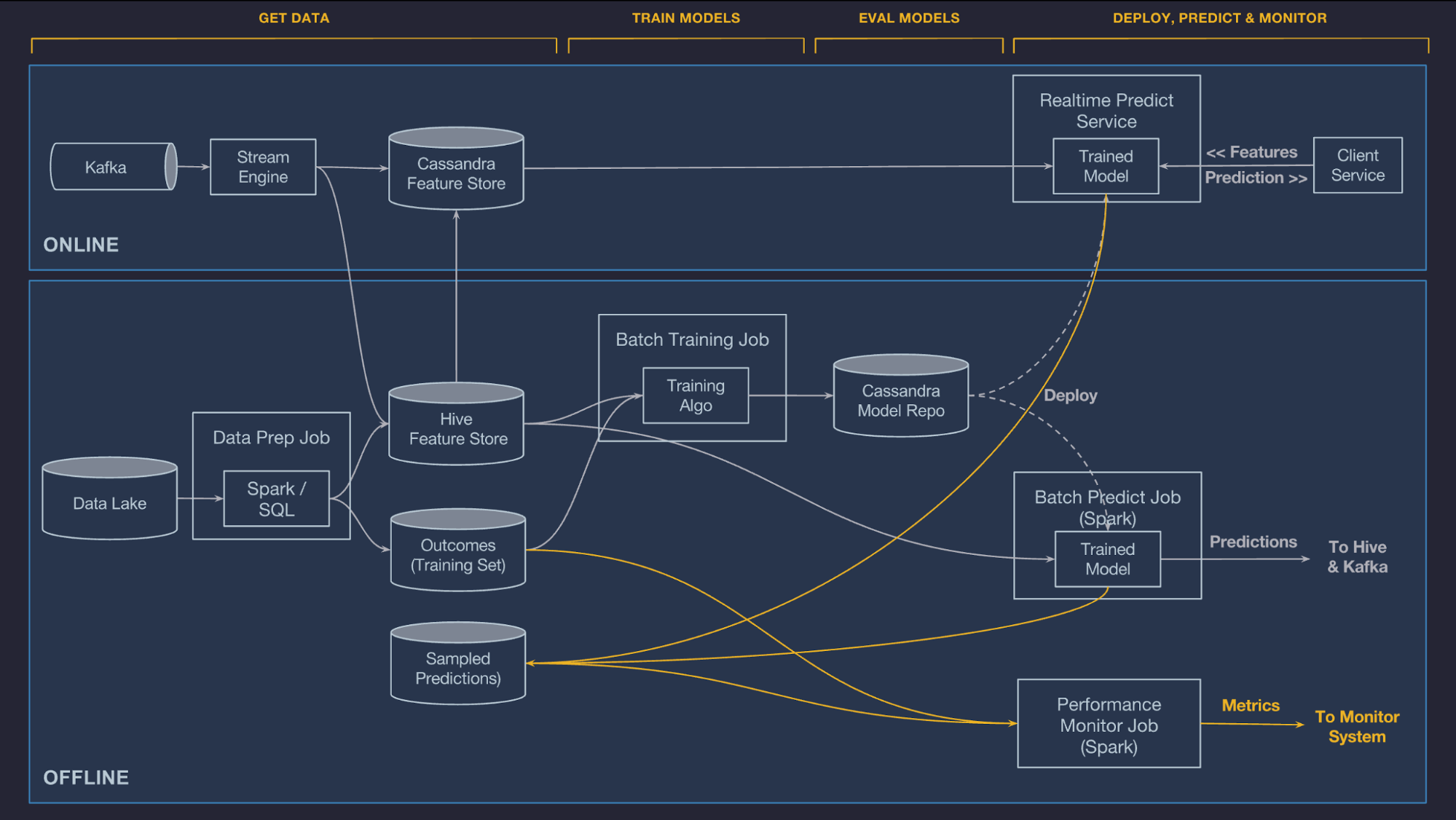
This difference in how features need to be created and accessed is a natural place for bugs to crop up. Harmonization of the online and offline processes would reduce bugs, so the Uber team, amongst others, introduced the concept of features stores to do just that. Members of the Uber team developed Tecton, a feature store company, which is one option to implement this system. An open-source alternative is Feast. To summarize, Tecton offers a handy definition of what a feature store is: “an ML-specific data system that runs data pipelines that transform raw data into feature values, stores and manages the feature data itself, and serves feature data consistently for training and inference purposes.”
A word of caution: don’t over-engineer your system according to what others are doing. It’s easy to wrap yourself up in adopting many tools and systems that aren’t as optimal as their publicity may make them seem. Work with the tools you have first! For an interesting example of this, look at how “command-line tools can be 235x faster than your Hadoop cluster”.
6 - Data Exploration
The objective of data exploration is to understand and visualize the nature of the data you’re modeling.
-
Pandas is the Python workhorse of data visualization. It’s highly recommended to be familiar with it.
-
Dask is an alternative that can speed up data processing for large datasets that Pandas cannot handle through parallelization.
-
Similarly, RAPIDS speeds up large dataset processing, though it does through the use of GPUs.
7 - Data Labeling
Effective data labeling is a core ingredient of production machine learning systems. Most data labeling platforms have a standard set of features: the ability to generate bounding boxes, segmentations, key points, class assignments, etc. The crucial objective is agreeing on what makes a good annotation and training annotators accordingly. To avoid annotator error cropping up, write clear guidelines that clarify rules for edge cases and high-quality annotations. One way to acquire the material needed to write such a guide is to start by annotating yourself. As you generate labels, ensure the quality of the annotations holds up across the annotator base. Some participants will be more reliable than others.
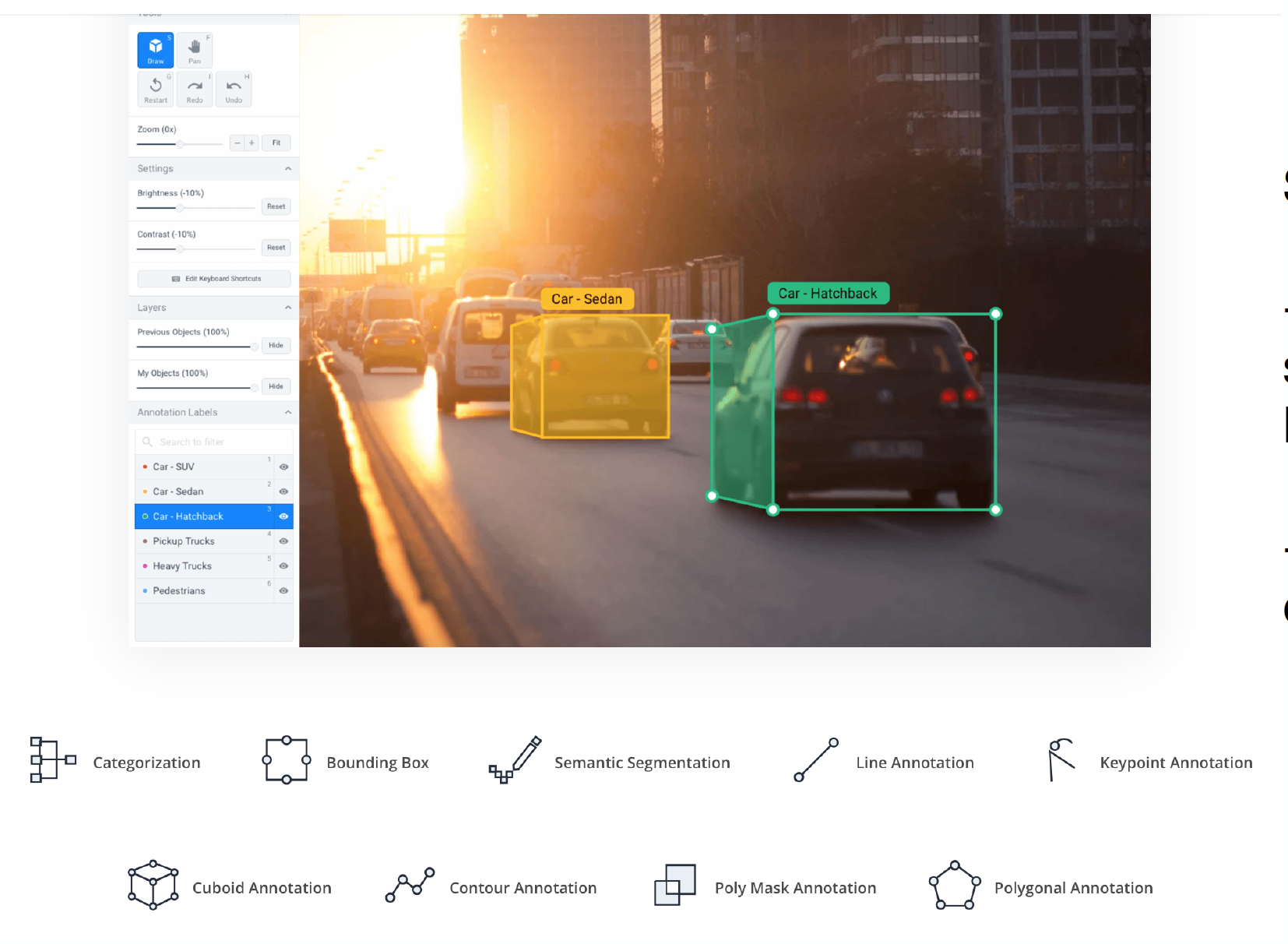
To develop an annotator base, there are a few options.
Sources of Labor
-
One option is to hire your own annotators, which can help with the speed and quality of annotations. This, however, can be expensive and difficult to scale.
-
Another option is to crowdsource labels via a platform like Amazon Mechanical Turk, which is fast and cheap to set up, but for which the quality can be poorer.
-
…or full-service data labeling companies.
Service Companies
There are entire service companies that focus on data labeling that you can hire. Hiring such a company makes a great deal of sense, considering the time, labor, and software investment needed to label well at scale. To figure out the best data labeling company, start by annotating some gold standard data yourself. Then, contact and evaluate several companies on their value and a sample labeling task. Some companies in this space are FigureEight, Scale.ai, Labelbox, and Supervisely.
Software
If the costs of a full-service data labeling company are prohibitive, pure-play labeling software can be an option.
-
Label Studio is a friendly open-source platform for this. New concepts to make labeling more strategic and efficient are coming to the fore.
-
Aquarium helps you explore your data extensively and map the appropriate labeling strategy for classes that may be less prevalent or performant.
-
Snorkel.ai offers a platform that incorporates weak supervision, which automatically labels data points based on heuristics and human feedback.
In summary, if you can afford not to label, don’t; get a full-service company to take care of it. Failing that, try to use existing software and a part-time annotator base work (in lieu of a crowdsourced workforce).
8 - Data Versioning
Data versioning is important because machine learning models are part code and part data. If the data isn’t versioned, the system isn’t fully versioned! There are four levels to data versioning, which is similar to code versioning:
Level 0: No versioning.
-
All data lives on a filesystem, in S3, and/or in a database.
-
The problem arises most acutely in this paradigm, as deployed ML systems (whose code may be versioned) can quickly become divorced from their corresponding data.
-
Furthermore, reverting to older versions will be challenging.
Level 1: Storing a snapshot of everything at training time.
-
This works and can help you revert, but it’s very hacky.
-
Rather than doing this entire process manually, let’s try to version automatically.
Level 2: Versioned as a mix of assets and code.
-
You store the large files with unique IDs in S3, with corresponding reference JSON versioned with code.
-
You should avoid storing the data directly in the repository, as the metadata itself can get pretty large. Using git-lfs lets you store them just as easily as code.
-
The git signature + of the raw data file fully defines a model’s data and code.
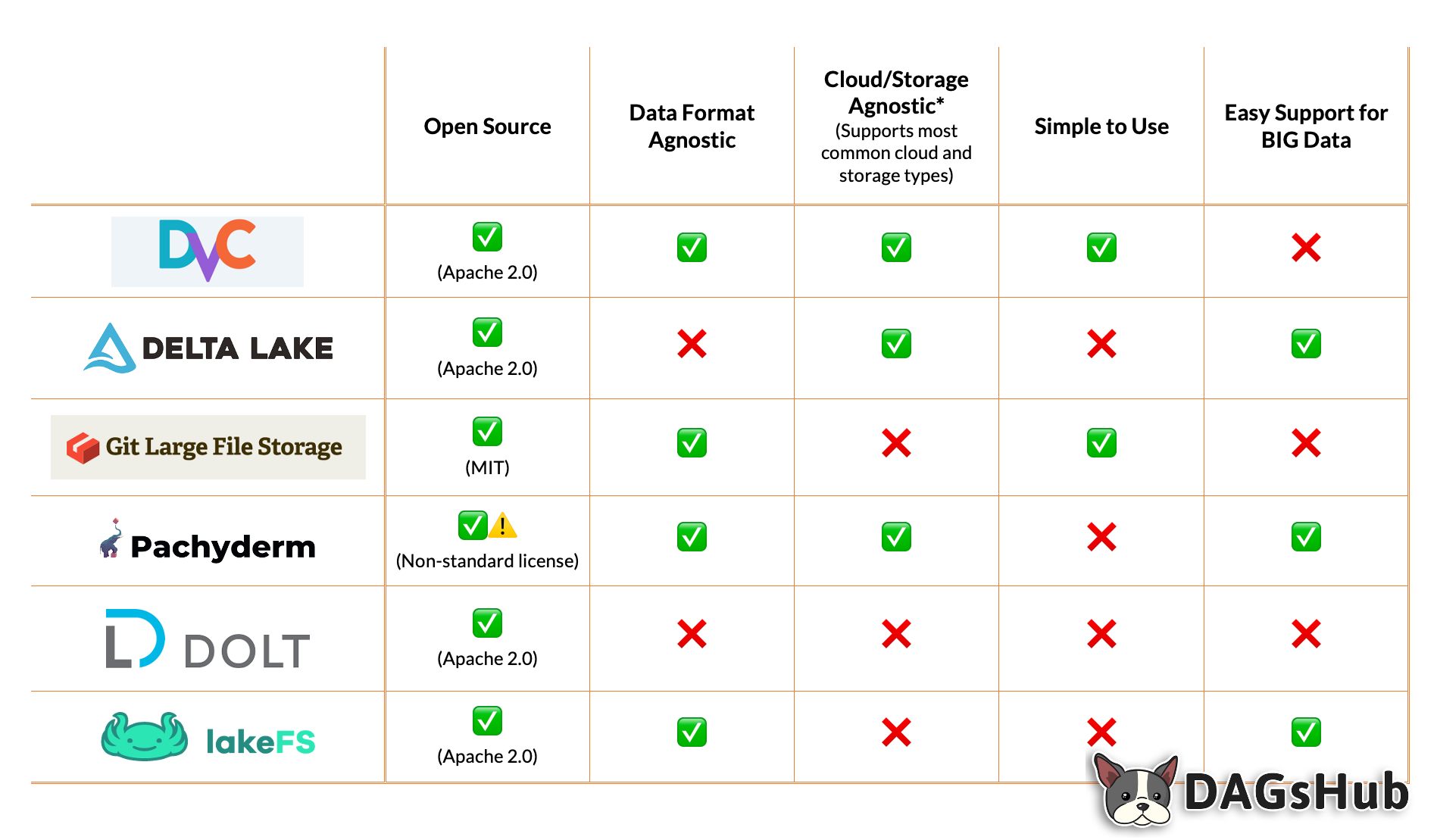
Level 3: Specialized solutions for version data.
-
You should avoid them until you can identify their unique value add to your project.
-
Some options here are DVC are Pachyderm. DVC has a Git-like workflow worth taking a closer look at. Dolt versions databases, if that’s your need.
9 - Data Privacy
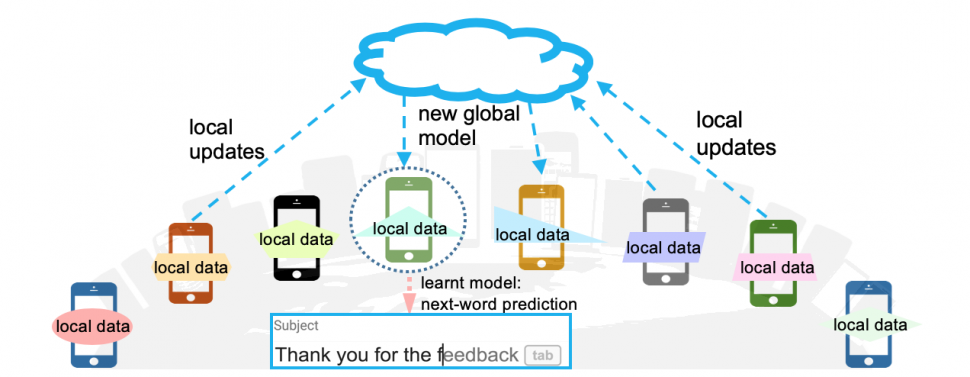
Increasingly, unfettered access to data for machine learning is less desirable and prevalent. This is especially true in regulated industries like healthcare and finance. To address such challenges, researchers are developing new data privacy techniques.
-
Federated learning trains a global model on several local devices without ever acquiring global access to the data. Federated learning is still research-use only due to these issues: (1) sending model updates can be expensive, (2) the depth of anonymization is not clear, and (3) system heterogeneity when it comes to training is unacceptably high.
-
Another research area is differential privacy, which tries to aggregate data in ways that prevent identification. Finally, learning on encrypted data has potential. Most data privacy efforts are research-focused, as the tooling is not yet mature.
We are excited to share this course with you for free.
We have more upcoming great content. Subscribe to stay up to date as we release it.
We take your privacy and attention very seriously and will never spam you. I am already a subscriber